Principal Component Analysis (PCA): Dimensionality Reduction & Insights
Principal Component Analysis (PCA) is a powerful technique used for dimensionality reduction. It transforms high-dimensional data into a smaller set of uncorrelated components while retaining the most significant variance. In this project, PCA was applied to identify patterns in food nutritional attributes and to reduce redundancy among features, making the dataset more interpretable for further analysis.
Data Preprocessing
Before applying PCA, the dataset underwent thorough preprocessing to ensure optimal results. Key steps included:
- Handling Missing Values: Missing numerical values were filled with column means, while categorical attributes were assigned a placeholder category.
- Feature Scaling: Since PCA is sensitive to feature magnitude, all numerical variables were standardized using Sklearn’s StandardScaler to ensure a mean of zero and a standard deviation of one.
- Feature Selection: Only numerical attributes related to macronutrient composition were retained, eliminating redundant categorical variables.

PCA Preprocessing
After standardization, the dataset was transformed into its principal components. The key steps in PCA preprocessing included:
- Covariance Matrix Calculation: Understanding how different features vary with respect to one another.
- Eigen Decomposition: Extracting the most significant principal components.
- Projection: Transforming the original dataset into the newly computed principal component space.
PCA Variance Retention Analysis
To determine the optimal number of components, cumulative variance analysis was conducted. The plot below demonstrates the number of principal components required to retain at least 95% of the total variance.
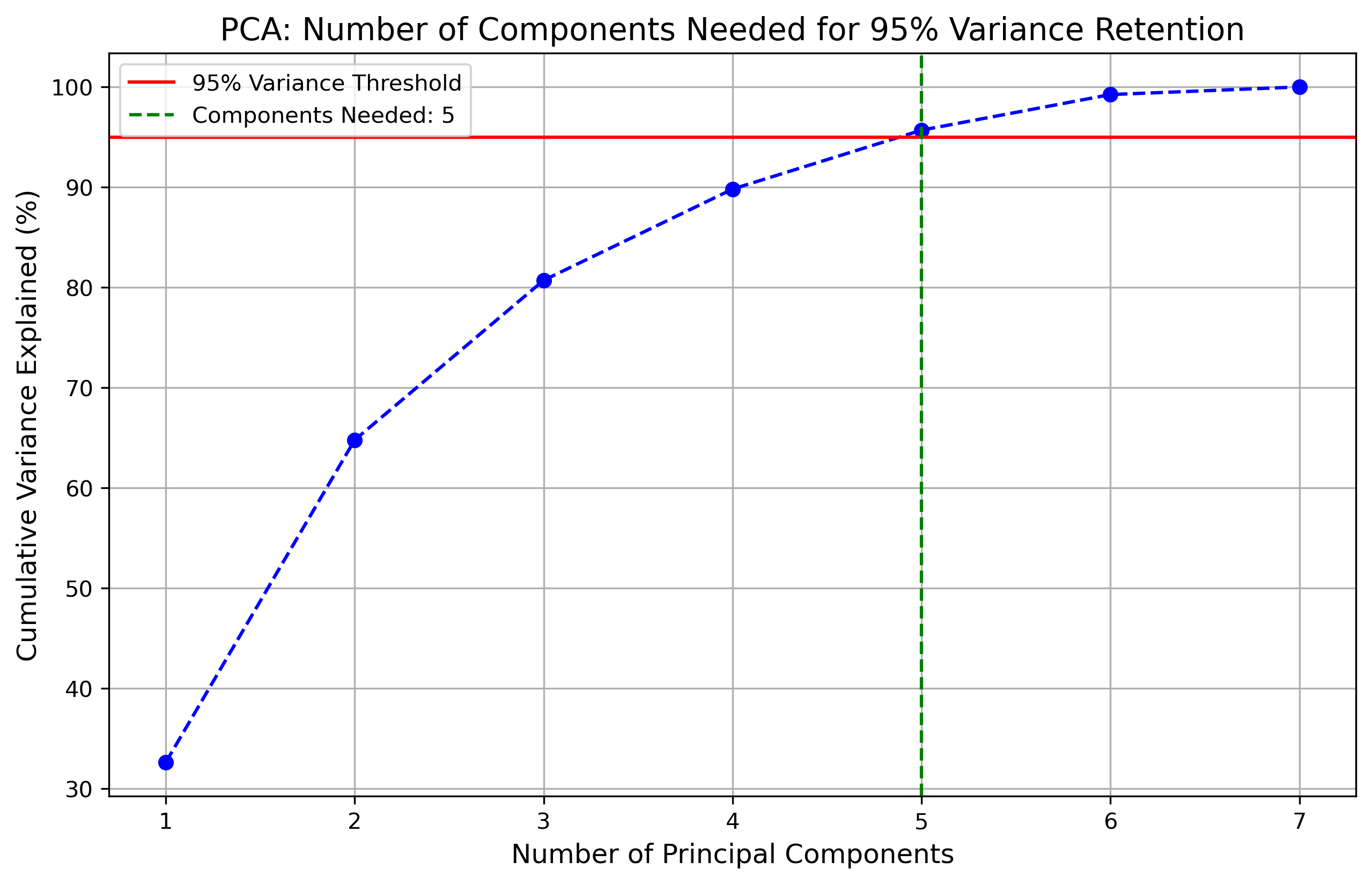
The analysis shows that five principal components are needed to retain 95% of the variance. This allows us to significantly reduce the dimensionality while preserving the most relevant information.
Eigenvalues of the Principal Components
Eigenvalues represent the amount of variance captured by each principal component. The larger the eigenvalue, the more significant the component. The top three eigenvalues are:
- First Principal Component: 2.283
- Second Principal Component: 2.251
- Third Principal Component: 1.115
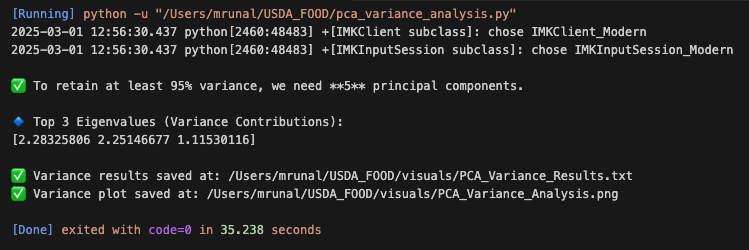
These values indicate that the first two components capture the majority of variance, making them highly valuable for feature reduction.
PCA Visualizations
The following visualizations show how the dataset was transformed into principal component space:
PCA 2D Projection
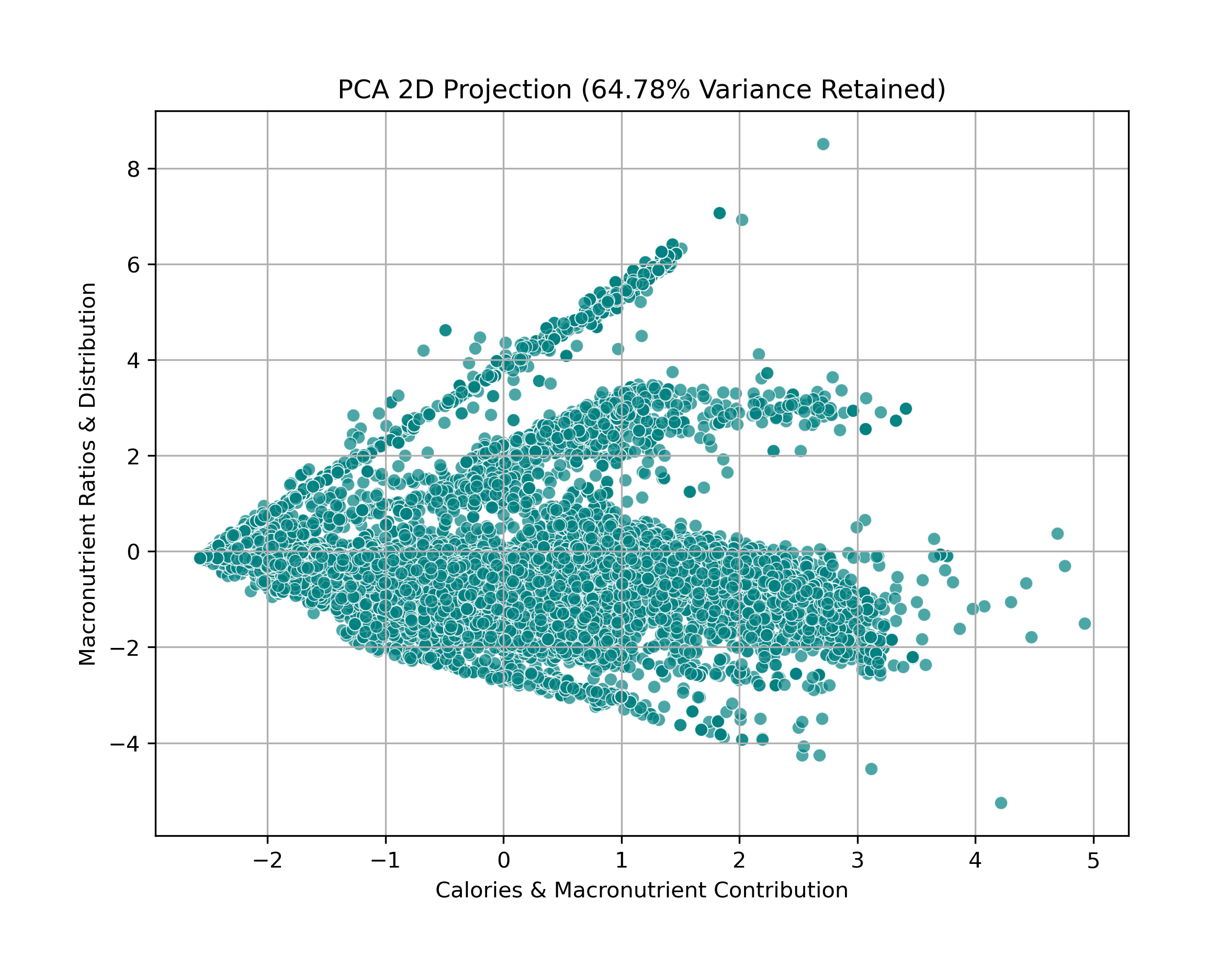
The 2D projection retains 64.78% of the variance. This visualization helps in identifying natural clusters of food items based on their macronutrient distribution.
PCA 3D Projection
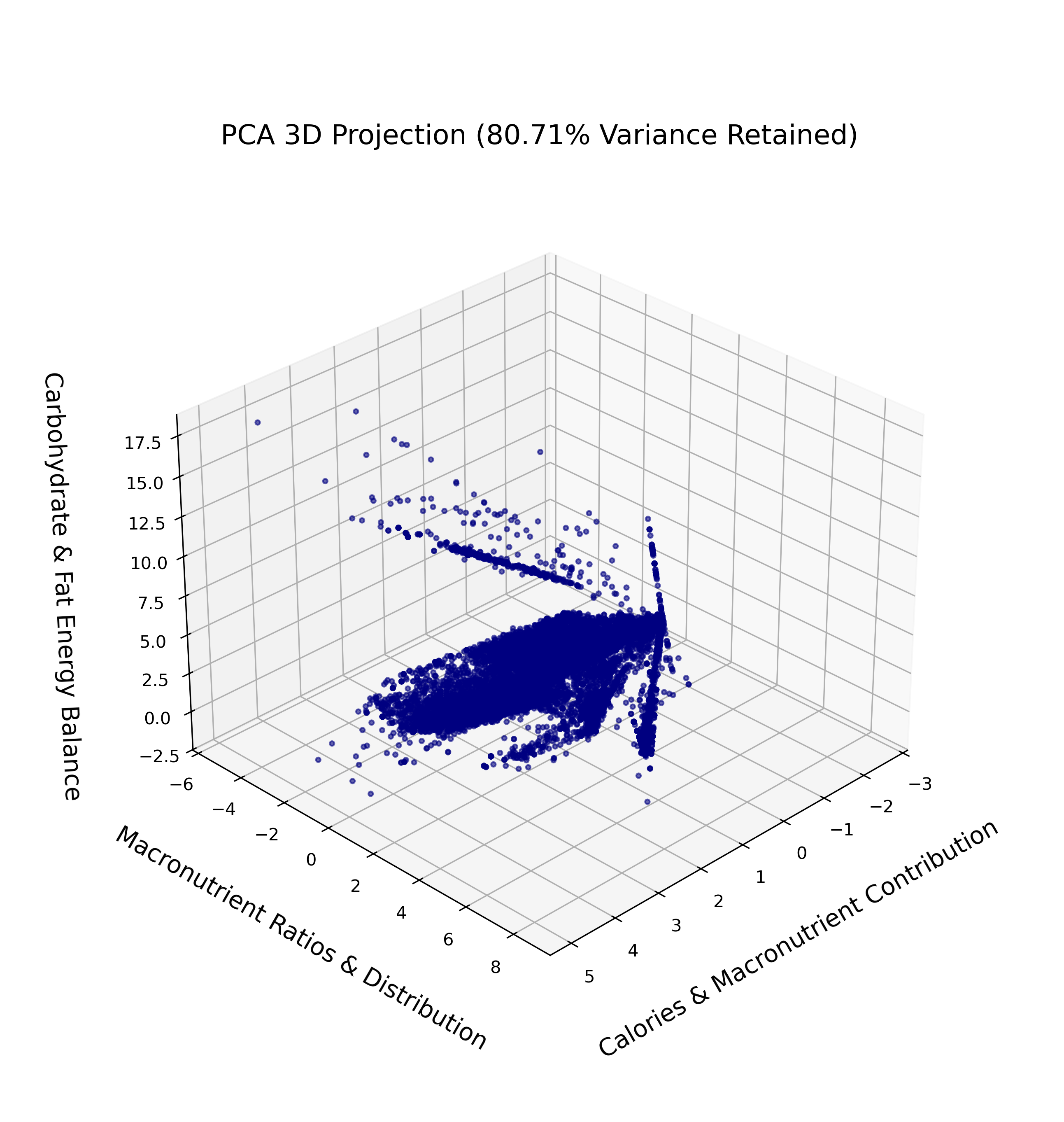
The 3D PCA projection retains 80.71% of the variance. This higher-dimensional representation provides better clarity on how different foods relate based on their nutritional attributes.
Key Findings & Insights
The PCA analysis revealed several important insights about food classification based on nutritional attributes:
- Dimensionality Reduction: Reducing the number of features from the original dataset to five principal components allowed us to preserve 95% of the total variance while eliminating redundancy.
- Macronutrient Clustering: Foods naturally group together based on their energy composition, with clear distinctions between high-carb, high-protein, and high-fat foods.
- Feature Importance: The first two principal components contain the majority of the variance, highlighting their dominant role in differentiating food categories.
- Interpretability: The PCA projections (2D & 3D) provide a structured visualization of food nutritional content, helping to uncover hidden patterns in food data.
Overall, PCA has proven to be a highly effective tool for analyzing large food datasets by reducing dimensionality without losing critical information. The transformed data can now be used for further analysis, such as clustering or predictive modeling, with greater efficiency and interpretability.
Conclusion
Principal Component Analysis (PCA) simplifies complex datasets, making them easier to understand and analyze. By breaking down large amounts of nutritional data into a few key components, PCA helps reveal hidden patterns that might otherwise go unnoticed. Instead of analyzing dozens of overlapping nutritional features, PCA condenses this information while keeping the most important aspects intact.
In this project, PCA was used to reduce redundancy in food nutritional data, allowing for a clearer comparison of different food items. By focusing on the most influential factors, we can categorize foods more effectively and identify relationships based on their true nutritional composition rather than just names or labels. This approach makes it easier to understand which foods share similar characteristics, helping in meal planning, diet optimization, and health-conscious decision-making.

The insights gained from PCA are not only useful for consumers but also for researchers and policymakers. With a more structured representation of nutritional data, it becomes possible to create better food categorization, refine dietary recommendations, and improve public health strategies. Whether it’s simplifying nutrition labels, identifying healthier alternatives, or personalizing diets, PCA provides a data-driven approach to making more informed choices.
Ultimately, PCA transforms raw nutritional data into actionable insights. By reducing complexity while preserving essential information, it paves the way for better food analysis, smarter eating habits, and a deeper understanding of what we consume.